Variables often store pieces of text, called strings, that will be drawn to the screen.
When a string is assigned to a variable, the text needs to be wrapped in
quotes. You can use either 'single' or "double" quotation marks. Otherwise PlotDevice will think the piece of text is the name of a variable:
txt = hello >>> NameError: name 'hello' is not defined
txt = "hello" print(txt) >>> hello
Strings are lists of characters
A string is like a list of individual characters. You can access each character in the string by putting the ‘index’ number in brackets. You can also access substrings by passing a start- and end-index spearated by a colon. Note that just like ‘slices’ of a list, the end-index is not included in the sub-range returned.
alphabet = "abcdefghijklmnopqrstuvwxyz" alphabet[0] # returns 'a' alphabet[-1] # 'z' alphabet[:4] # 'abcd' alphabet[1:4] # 'bcd' alphabet[-3:] # 'xyz'
The choice() command selects either a random element from a list or a random character from a string (depending on which kind of value you pass to it). In the example below, we use choice() and random() to select 80 characters from the alphabet and scatter them over the screen at random positions, sizes, and orientations.
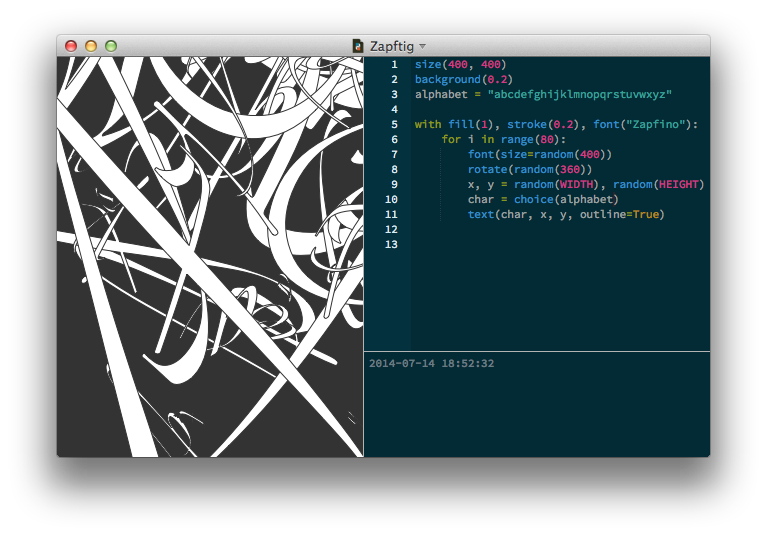
Manipulating strings
Python strings have a number of very useful methods:
str.upper()
returns an uppercase copy of the string
str.lower()
returns a lowercase copy of the string
str.capitalize()
returns a copy of the string with the first character capitalized
str.title()
returns a copy of the string with the first character of each word capitalized
str.find(txt, start=0)
returns the index position of txt in the string
str.replace(old, new)
returns a copy of the string with all instances of old replaced by new
str.split()
returns the list of words (separated by whitespace) in the string
str.join(lst)
returns a string formed by concatenating all the items of lst with str separating them
Keep in mind that these are methods of the string object itself, not commands. So rather than calling then with your string as an argument:
lower(txt) # bzzzt, wrong
you need to use ‘dot notation’ to access the string’s method instead:
txt.lower() # hooray, success
All the string methods leave your original string untouched and instead return a new copy that’s been modified accordingly:
txt = "Ask me, ask me, ask me" print(txt.title()) print(txt.upper()) print(txt) >>> Ask Me, Ask Me, Ask Me >>> ASK ME, ASK ME, ASK ME >>> Ask me, ask me, ask me
The replace() method is especially useful when you want to filter mistakes from the string or otherwise alter portions of the content:
txt = "There's more to life than code, you know." txt = txt.replace("code", "books") txt = txt.replace(".", ". But not much more...") print(txt) >>> There's more to life than books, you know. But not much more...
If your search & replace needs are more complex, Python has a powerful Regular Expressions library available to you. Add import re to the top of your script and you’ll have access to useful methods like:
- re.search(regex, str): return a match if the pattern was found in str or
Noneif it wasn’t. - re.sub(regex, new, orig): return a string derived from orig in which each occurrance of a pattern is replaced with new.
- re.split(regex, str): return a list of substrings, using the pattern to divide the original string.
String formatting
We’ve seen that the print statement allows you to combine multiple variables when generating output. It even adds a space character between terms separated by commas. But mixing strings and values like this gets hard to edit as your code gets more complex. An alternative approach is to use ‘string interpolation’ to generate a new string with your values inserted at specific locations according to a template.
Python has two syntaxes for this: the ‘new’ style using the string’s format() method, and the ‘old’ style using printf-style escapes and the % operator. Personally, I still prefer the older approach, but your mileage may vary.
Here’s an old-style formatting example. The basic usage is template % values. If you’re inserting multiple values, be sure to wrap them in parentheses separated by commas:
pastry = 'pie' num = [4, 20] price = 12.5 txt = '%i & %i blackbirds baked in a %s: $%0.2f' % (num[0], num[1], pastry, price) print(txt) >>> 4 & 20 blackbirds baked in a pie: $12.50
If you want your string to contain a literal "%" character, put a "%%" in your format instead:
print("(plus %i%% sales tax)" % 5) >>> (plus 5% sales tax)
Quotes in quotes
Text strings often contain quotation marks as content, especially if the text contains dialogue. When PlotDevice examines the string and encounters such a quote, it would logically assume that the string is terminated here.
For instance, the following example won’t work:
txt = "(On his death bed): "Those curtains are hideous." - Oscar Wilde"
PlotDevice sees "(On his death bed): " as a complete string followed by garbage statements it doesn’t understand.
To get around this, take your pick of either double- or single-quotes when defining a string. Whichever one you start the string with will also be used for determining where the string ends. If double-quotes are part of the content of our string, we might choose to wrap it in single-quotes (and vice versa):
txt = '(On his death bed): "Those curtains are hideous." - Oscar Wilde'
Or, if we’ve got a lot of single-quotes in the content, we can wrap it in double-quotes:
txt = "You can't / you won't / and you don't / stop."
But if our string contains both kinds of quotes, this approach doesn’t help us. For these cases we can use triple-quotes to delimit the string and mix-and-match quotation marks within it:
txt = """John Cage's 4'33" (performed by the Boston Typewriter Orchestra)"""
Triple-quoted strings are also unique in being able to span multiple lines. Each carriage return will be converted to a newline character in the string it assigns. Single- and double-quoted strings must begin and end on the same line of your script. If you want to include line breaks in a non-triple-quoted string, use the ‘escape’ code for the newline character: "\n".
File input
When you’re going to typeset long paragraphs of text, it’s better to store the text in a separate text file and then read its contents into a variable. This keeps your script clean, and you can edit the text separately from the script.
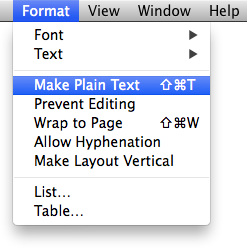
The text file you create must be plain text devoid of styling (PlotDevice doesn’t speak RTF or .docx). If you use a text-editor like Sublime Text, TextMate, or Emacs any files you create will be plaintext by default. If you’re using the built-in TextEdit application, the first thing you’ll need to do upon creating a new document is disable formatting:
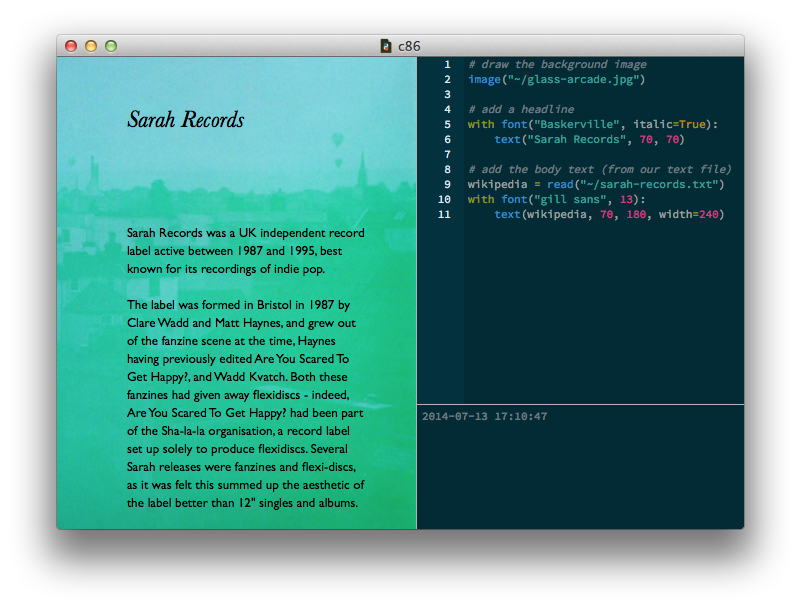
You can then compose whatever text you’d like (or, if you’re like me, lazily paste in something interesting from Wikipedia). Save the file to a convenient folder and remember its file path so you can access it from your script:

Within our PlotDevice script, we can read the contents of the file into a string using the read() command. Note that when we draw the string (by passing it to text()) we make sure to include a width argument. Otherwise there’d be no line-breaking and text would go spilling off the right side of the canvas:
Unicode characters
Unicode is a character system that allows computers to use symbols from all of the writing systems in the world. If you’re going to use for example suomi or Hebrew in the output of your script, you’ll have to know about Unicode.
If you’re going to import text from a text file, the first thing to ensure is that the file has been saved in a compatible ‘text encoding’. In the dark ages of the 1990s there were dozens of encodings in common usage – with most only being useful for one language or another. Thankfully, the world has mostly converged on UTF-8 as the One True Encoding in recent years and we recommend that you use it for all your data and source code files.
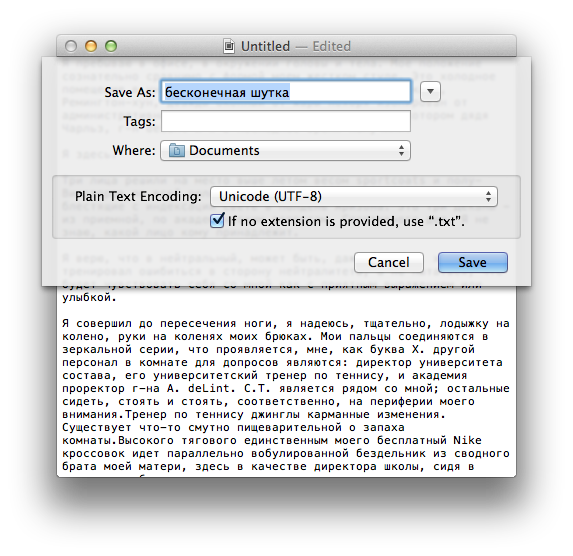
When saving a plain text document in TextEdit, make sure is selected in the list:
You can load the file’s contents into by calling the read() command with a filename or url. It reads the file’s raw bytes and decodes them, returning a unicode string.
txt = read("proust.txt")
By default it will attempt to decode the file as UTF-8, but if you pass an optional encoding argument you can override this.
txt = read("ozu.txt", encoding="shift-jis")
The read() command is just a convenience method. You can emulate its behavior using standard Python functions if you’d rather do things by-the-book:
raw_bytes = file("hebrew.txt").read() txt = raw_bytes.decode("utf-8") text(txt, 100, 200)